Databases & SQL for beginners
Let me guess, you have been thinking of and planning to start transitioning into or jumping directly into a career into Data related job roles, including but not limited to, Data Analytics, Data Engineering, Data Modelling, etc and the first thing you have been suggested by people in these fields is to learn about data and SQL.
Well, I'm here just to help you through that. Databases and SQL is one of the most crucial concepts in my opinion - which you will use for the rest of your professional life in case you decide to pursue your career in data related roles, and while everyone wants to eventually start with the practical stuff, it's equally crucial to understand how it works in theory, not only because it will help you in interviews, but this will help you understand your everyday work better and solve problems by understanding the concepts at core. So, without wasting more of your precious time, I'll jump right into it.
What is a database?
To keep the language simple, imagine a big container filled with smaller boxes or containers of varying sizes, which may also be linked to one another through some properties or attributes. These boxes have the ability to store a ton of information inside them and helps to organise information better according to the users' needs.
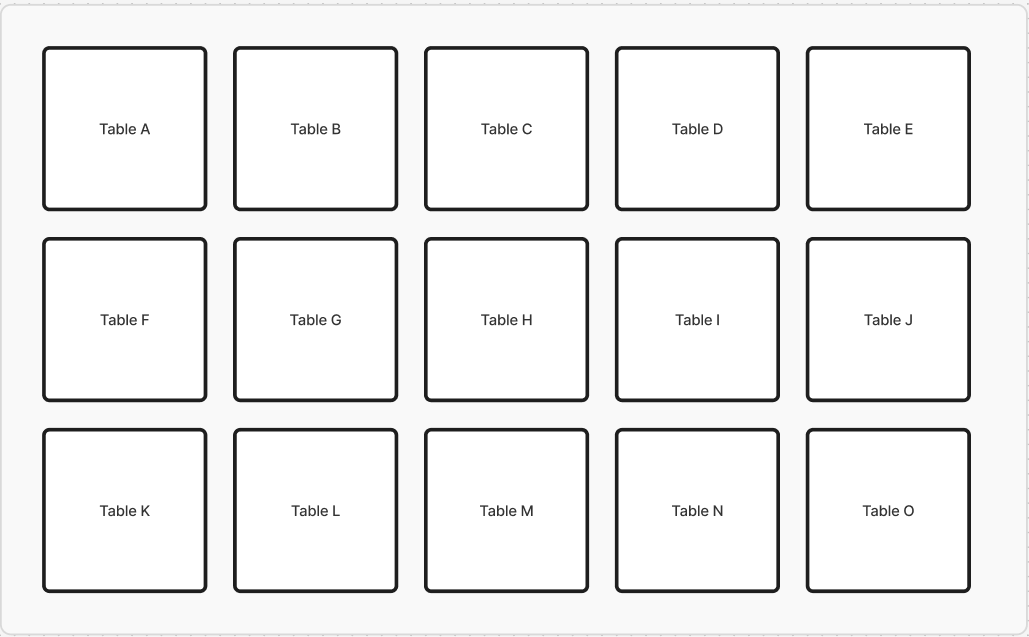
In the diagram 1 - You can see 15 tables from A-O inside a larger container. While these tables have their own storage, they also have the ability to be linked to each through their primary identifying attributes.
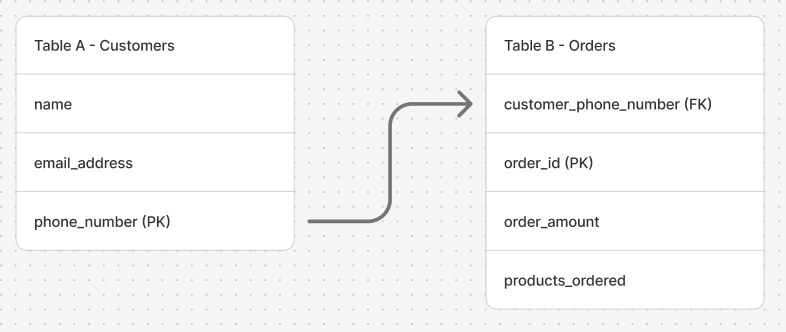
For example - Let's assume that Table A is used to store a list of customers for an e-commerce store and holds information such as their name, email address and phone number and Table B stores the list of orders for all the customers and stores information such as which customer placed the order, for how much amount and for what products. Assuming the engineer configured the table in such a way that the primary attribute which uniquely identifies a customer in Table A is the phone number (This will be called the "Primary Key" for Table A), in order to link Table A to Table B, the engineer would also create a "Foreign Key" in Table B which acts as the link between Table A and Table B. The Foreign Key holds the same value as it would in the Primary Key in Table A - so, Table B would hold the phone number of the customer who placed the order as a Foreign Key. You can visualise it better through Diagram 2.
Just to be transparent, attributes such as phone numbers, even though unique, may not be used as a primary key by most companies, the reason being that such fields are usually a part of PII (Personally Identifiable Information) information which is usually a sensitive set of data which most companies protect even from their internal employees and is shared only with those who absolutely need to work with or on the basis of PII information with certain policies in place which protect that set of information.
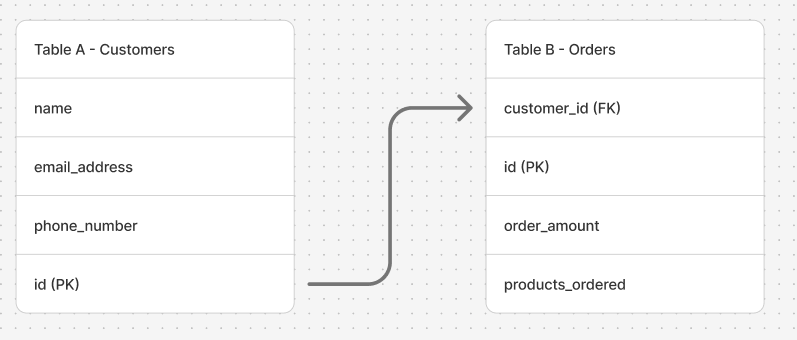
So what do companies use in place of PII information to create Primary Keys? They use simple integers or an alphanumeric IDs (commonly known as UUIDs) to create a unique identification as a primary key for each table. These keys are then used as foreign keys in subsequent tables which need to be linked together. So the tables in Diagram 2 would probably look a little different in the real world - as shown in Diagram 3.
ACID Properties
Now that you've some understanding of how databases look like in general - there are some rules / properties which need to be kept in mind while creating or working with databases - also commonly known as A.C.I.D. properties.
A - Atomicity
The idea behind atomicity is to maintain the integrity of a transaction. A transaction in databases can be a simple write transaction to your database, for example, you work for a company which provides a digital wallet to it's customers to use for faster and smoother payments, for them a simple transaction could be one customer paying to another customer paying some amount of money.
Let's say for that transaction, a customer X wants to send 100 bucks to customer Y through the wallet, then there are two sub transactions taking place in the database for this:
- Transaction 1: Debit 100 from X's wallet
- Transaction 2: Credit 100 from Y's wallet
What happens if transaction 1 succeeds but while transaction 2 is taking place, some error comes up in the system because of which it fails? If atomicity is not taken care, 100 bucks will get deducted from X's wallet by Y will never receive the money, thus leading to a faulty transaction. Therefore, atomicity states that the transaction as a whole will be considered successful if all the sub-transactions are successful, failing which the entire transaction shall be marked as a failure and all the changes, if any, shall be rolled backed to it's original state.
C - Consistency
Consistency can be considered as an extension to Atomicity. It states that after each operation, the database state should stay consistent before and after the transaction. Extending the example given above - considering the Transaction was successful, if 100 bucks from debited from X and credited to Y, the net amount should still be 100 in the system and not change. Consider a scenario where the transaction above failed, and because atomicity was not followed, 100 bucks got debited from the customer's wallet but Y didn't receive them. In terms of the database, the amount is now 100 bucks less because while there was a debit of that money, it never got credited, so the net change in the amount in system is now -100 instead of 0.
I - Isolation
Isolation states that multiple transactions should be able to occur independently and concurrently without waiting for previous transactions to finish while also maintaining the consistency and atomicity.
Continuing the example given in Atomicity, there would definitely be multiple users in the system who would be doing transactions between themselves at the same time, if the transactions are not allowed to be independently driven, each customer will have to wait for the previous transaction to be finished before they can start with their transaction. This poses another problem - Let's say that a customer Z has a total of 200 bucks as their wallet balance and they owe a total of 300 bucks to two different customers, X and Y (150 each).
If customer Z somehow initiates both the transactions one after the other, the system should be able to handle the transactions in a way where the first initiated transaction by the customer Z should make their wallet balance fall to 50 bucks which is insufficient for the second transaction even if the first transaction is still in progress, and should throw an error to the customer for the second transaction.
This is because if these properties are not followed, because when the customer initiated the second transaction at the same time as the first, the wallet balance would still have been the same and the customer would have been able to make two debit transactions of total 300 bucks on a wallet balance of 200 bucks.
D - Durability
Durability states that after each transaction, the updates and modifications and logs shall be stored in a disk so that the data persists even after a system failure. The effects of the transactions should never be lost
Types of Databases
There are broadly two types of databases, Relational Databases and No-SQL (Non SQL) databases.
Relational Databases
These kinds of databases are structured in nature, usually structured in rows and columns. These are the most commonly used kinds of databases in the industry and can handle complex transactions. Once a schema is defined for a table, all records in the table must follow the same schema. If a new attribute/column needs to be added in the table, then the attribute should also be assigned a value (default or by some custom logic) for all the previous records in the table as well.
No-SQL Databases
These kinds of databases are usually non-structured and are better for transactions which are simpler in nature. Every record can have a different schema inside the tables giving more flexibility for adding attributes without needing to add values for historical data.
One key difference between No-SQL and Relational Databases is the volume of data - generally speaking, No-SQL databases are preferred for use cases where the volume of data is very high because of it's unstructured nature and the ability to transform the data structure as per the requirements. On the contrary - use cases where more complex transactions or logics needs to be performed, relational databases are usually the go-to choice.
One example which comes to mind is - E-Commerce related data is usually stored in relational databases however the application and code logs maybe stored in a non-sql database since the volume of logs is high and generally don't require any complex computations.
I have also uploaded a youtube video on this topic which you can watch as well for more detailed explanation